Hoe je het crawlen en indexeren van je website onder controle houdt

Zoekmachinespiders zoals de Googlebot en Bingbot gaan bij hun bezoek aan je website altijd op zoek naar crawl-instructies; dit kan op een aantal manieren worden aangegeven en zo zorg je dat spiders zichzelf beter wegwijs maken binnen jouw website. Wat zijn o.a. die crawl-instructies?
- Uitsluiten van specifieke spider(s) (User-agents)
- Wel of niet indexeren van content en/of URL’s
- Wel of niet volgen van links
- Laten zien waar je XML sitemap staat
Waarmee kun je die instructies doorgeven?
- robots.txt-bestand
- meta tag robots
- x-robots tag
Bij de keuze voor het gebruik van 1 of meerdere methodes is het belangrijk dat je weet wat de voordelen en nadelen zijn. Dit artikel vertelt het in 5 minuten.
1. Robots.txt bestand
Wat is het?
De Robots.txt is een tekstbestand dat voor elke website kan worden geactiveerd. Dit is het eerste bestand waar een spider naar zoekt voordat het begint met crawlen van je site.
Waar kan ik het vinden?
Als het bestand geactiveerd is kun je het vinden door /robots.txt achter je domeinnaam te zetten.
Bijvoorbeeld: https://maxlead.com/robots.txt.
Het is in de SEO wereld waarschijnlijk het meest bekende begrip voor het wel of niet indexeren van de content binnen je webpagina’s.
Geef eens een voorbeeld waarom ik het zou gebruiken?
Het Robots.txt bestand sluit vooral de content uit van indexatie, niet perse de URL (instructie: Disallow).
Wat zou je dan kunnen of willen uitsluiten van indexatie?
Voorbeeld 1: Dynamische filterpagina’s
Deze kom je met name tegen binnen een e-commerce platform. Het mooie van zo’n systeem is dat een bezoeker kan filteren op specifieke producteigenschappen, het nadeel is dat het heel veel (vanuit SEO-optiek) onnodige URL’s kan genereren die je eigenlijk niet wil laten crawlen (veelal duplicate of shallow content). Via de robots.txt kun je aangeven dat de content van filterpagina’s niet geïndexeerd mogen worden. Voorbeeld van een filterpagina: jouwwebsite.nl/schoenen/hardloopschoenen/?cat=346&prod=4859&maat=38&kleur=zwart
Als je niet uitkijkt kunnen filterpagina’s qua aantallen oplopen tot het oneindige. Uitsluiten van filterpagina’s kan dan ten goede komen van de kwaliteit van je website en het crawlbudget; dit laatste is de hoeveelheid pagina’s die een zoekmachinespider crawlt tijdens een bezoek aan jouw website. Maak daarom dus een goede selectie en bepaal wat niet gecrawld hoeft te worden.
Voorbeeld 2: Uitsluiten van test- of acceptatie-omgeving
Deze omgeving wordt vaak gebruik tijdens een redesign van je site of om nieuwe templates of elementen te testen alvorens ze te implementeren op de live-omgeving. Niet onbelangrijk is om deze omgeving uit de zoekmachine-index te houden. Gebruik dan als optie de instructie Disallow: /
Let wel heel goed op dat bij livegang deze versie van de robots.txt niet live komt te staan!
Kan ik de robots.txt zelf instellen?
9 van de 10 keer heb je de webbouwer of hosting provider nodig om het robots.txt bestand in te richten. Sommige Content Management Systemen (CMS-en) geven de optie het zelf in te stellen of aan te passen.
Let op: wees heel heel voorzichtig met zelf invullen van het robots.txt bestand, schakel altijd een deskundige in, want voor je het weet wordt jouw content niet meer gecrawld en kunnen zoekmachinespiders er geen relevantie meer aan toekennen. Met andere woorden: dit kan resulteren in verlies van organisch verkeer.
Moet ik het wel gebruiken?
Het Robots.txt bestand hoeft niet per se actief te zijn, mag best een HTTP 404 Not Found statuscode hebben. Zonder dit bestand wordt simpelweg de hele website gecrawld (als er binnen de pagina’s zelf geen andere signalen worden afgegeven).
Wij adviseren over het algemeen de robots.txt wel te activeren en simpelweg leeglaten als je niets hebt om uit te sluiten, of voeg alleen de XML sitemap toe.
Ga voor extra informatie over Robots.txt naar de SEO kennisbank op onze website of kijk hier.
2. Meta Tag Robots
Wat is het?
Zoals de benaming al een beetje verraadt is het een ‘meta tag’ die 1 of meer signalen afgeeft wat spiders wel of niet mogen.
Wat is het verschil met de robots.txt?
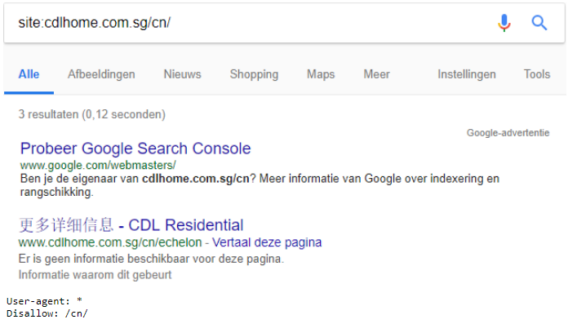
De meta tag robots geeft een sterker signaal af dan het robots.txt-bestand. De ‘Disallow’ instructie bij de robots.txt zegt “De content op de pagina mag niet geïndexeerd worden”. Het kan dus voorkomen dat URL’s toch verschijnen in de zoekmachine resultaten terwijl de ingang in het robots.txt bestand op disallow staan.
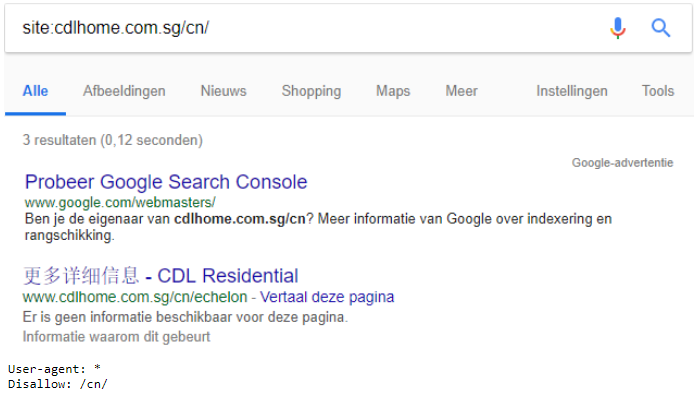
De ‘noindex’ instructie bij de meta tag robots zegt “indexeer zowel de content als de URL niet”. De ‘noindex’ geeft niet aan dat de links niet gevolgd mogen worden, dit moet je in dezelfde tag aangeven via de ‘nofollow’ instructie. Gebruik maar 1 meta tag robots per pagina.
Waar kan ik het vinden in mijn website?
Je kunt de meta tag robots vinden in de <head> van de broncode.
Voorbeeld van de tag die zegt “deze pagina mag niet geïndexeerd worden en volg niet de links op deze pagina”:
<meta name=”robots” content=”noindex, nofollow” />
Als het signaal binnen de <body> wordt geïmplementeerd, wordt deze genegeerd door de zoekmachinespiders. Check ook altijd of er meerdere tags in staan, er is een grote kans dat dan 1 of meer worden genegeerd, en je weet niet altijd welke. Google geeft aan dat als hun crawlers tegenstrijdige instructies aantreffen, zij de instructie gebruiken die de meeste beperkingen oplegt.
3. HTTP-header X-Robots-Tag
Wat is het en hoe ziet het eruit?
Dit is tevens een tag die crawl en indexatie instructies doorgeeft maar dan op serverniveau via de HTTP-header. Dat klinkt wat nerderig en voor de niet-techneuten ziet het er ook zo uit. Hieronder een instructie wat vertelt dat een pagina niet geïndexeerd mag worden:
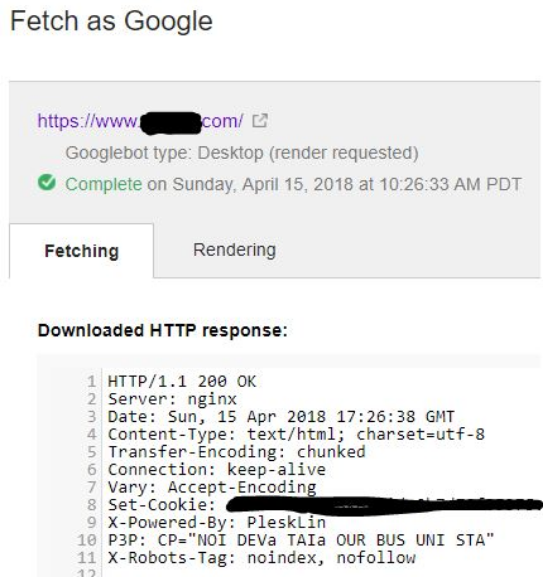
(uit Google Search Console)
Het voordeel van het gebruik van een X-Robots-Tag met HTTP-reacties is dat je verschillende instructies kunt meegeven.
Bijvoorbeeld voor de hele website, op pagina niveau, maar ook aan niet-HTML bestanden waar dat met een meta tag robots niet lukt.
Hoe kan ik de X-robots-tag checken?
Deze is wat ingewikkelder want je ziet de X-Robots-tag niet terugkomen in de broncode van een pagina. En toch zijn er een aantal mogelijkheden om te zien of deze tag wordt ingezet. Hoe?
Bij Maxlead gebruiken wij de SEO tool Screaming Frog; onder het onderdeel ‘directives’ vind je de X-Robots tag terug. Er is een gratis versie van Screaming Frog, deze crawlt tot 500 pagina’s van een website. Dat moet voldoende zijn om de X-Robots-Tag te kunnen detecteren als deze überhaupt wordt gebruikt.
Je kunt de tag ook via een chrome extensie als ‘Seerobots’ vinden.
Wel handig om te controleren want het gebruik van meerdere methodes wordt sterk afgeraden (het een kan het ander overrulen).
Lees meer over de X-Robots tag.
Overzicht van de 3 opties
Hieronder hebben we een tabel gemaakt van de 3 opties inclusief:
- voor- en nadelen
- welke instructies horen waar bij
- waarom je het zou gebruiken
Wellicht dat dat helpt bij je keuze wat waar in te zetten.
| Voordelen | Nadelen | Instructies | Waarom? | |
| Robots.txt |
|
|
|
|
| Meta Tag Robots |
|
|
|
|
| X-Robots Tag |
|
|
|
|
Standaard (default) gedrag van zoekmachinespiders is dat zij alle URL’s willen indexeren en volgen. Dit hoef je niet expliciet mee te geven. Tenzij een directory of pagina op ‘Disallow’ staat, dien je dit aan te passen naar ‘Allow’. Bij andere methodes volstaat het verwijderen van de ‘Noindex’ of ‘Nofollow’ instructie.
Moet ik nu elke dag kijken of de boel nog wel goed staat?
Dat zou gekkenwerk zijn als je regelmatig moet checken of de crawlsignalen van je website goed staan. Gelukkig is daar tooling voor die je waarschuwt als iets gewijzigd is. De tool die wij gebruiken is ContentKing. Via e-mail ontvang je notificaties als bijvoorbeeld je robots.txt verwijderd is, of een aantal meta tag robots zijn veranderd. Die notificaties worden trouwens voor meer SEO signalen afgevuurd zoals aanpassingen in Headings, title-tag, meta description of verandering van statuscodes. Zo kun je je focussen op je eigen werkzaamheden terwijl de tool je website in de gaten houdt. Uiteraard is een tool een tool en dus altijd goed zelf ook zo nu en dan te kijken hoe het ervoor staat.
Voorbeeld van een E-mail notificatie over een robots.txt verwijdering:

Conclusie
Bij je keuze voor een bepaalde methode is het belangrijk dat je kijkt naar wat het precies doet en dat je er voor zorgt dat bij gebruik van meerdere methodes de informatie niet tegenstrijdig is.
Binnen Maxlead kijken we per klant naar de situatie om een gedegen advies te kunnen geven. Indien de robots.txt niet volstaat, maak dan gebruik van de meta tag robots. Deze geeft een sterker signaal af en hierbij kun je, zoals hierboven beschreven, meerdere instructies meegeven. De X-robots-tag wordt alleen geadviseerd indien er hele specifieke instructies moeten worden meegegeven aan pagina’s of als de webbouwer deze voorkeur heeft.
Elke methode heeft zo z’n voor- en nadelen. Nog wel het allerbelangrijkste advies: zorg dat wat je geïndexeerd wilt hebben geïndexeerd kan worden en dat je optimaal gebruik maakt van je crawlbudget.
Meer weten over crawl- en indexatie-instructies?
Wil je meer informatie, advies en assistentie over dit onderwerp of over technische SEO in het algemeen? Neem dan contact op met een van onze specialisten.













